
a New Generation Search Engine with Multimodal Deep Learning
a New Generation Search Engine with Multimodal Deep Learning
Introduction
With a notable 91% of people desiring more video content from brands and a significant 85% of American internet users engaging with online video, the digital sphere is clearly dominated by video content. Its influence is also seen in driving purchasing decisions. This rise underscores the value of video and emphasizes the growing necessity for effective video search tools.
Searching video content presents substantial challenges. Typically, traditional video searches rely on keyword queries that reference user-defined metadata — titles, tags, descriptions, etc. Unfortunately, the metadata of most video is sparse or non-existent due to the reliance on video creators to provide.
When encountering a dearth of metadata, machine learning models can enrich the available video context for enhanced searchability. These models, commonly used as annotators, generate a set of signals and tags. However, most of current solutions typically focus on a single modality, excelling at resolving specific tasks tied to particular types of input.
For example, ‘Video Captioning’ models adeptly describe the featured actions and behaviors in video content. Likewise, ‘Automatic Speech Recognition’ (ASR) models seamlessly convert speech into text while ‘Optical Character Recognition’ (OCR) models are proficient at recognizing text within images or videos. Some NLP models shine in summarizing and refining text information, yielding useful tags extracted from viewer comments.
Despite these advances, specific video search requirements can challenge even the most advanced models, especially when a search requires processing multiple modalities simultaneously. Imagine a user wanting to retrieve a specific video moment featuring a particular speaker discussing a specific topic in a designated location. Single modality models struggle with such requests due to their ability to process only one type of data at a time.
This is where my proposition comes into play: using multimodal models to fulfill both content summaries and enrich video context during the video search indexing process. By integrating and correlating information from various modalities, these models can deliver a more comprehensive and accurate understanding of video content. Thus, they can significantly enhance video search performance to meet complex user search demands.
What multimodal models can bring in for video search
Multimodal models can be applied to multiple positions on the search link, such as query understanding and ranking, etc. This article only discusses its application in the indexing part, mainly reflected in the following tasks:
- Vision-Language
- Video-Text Retrieval: Mutual retrieval of image/video and text.
- Video Captioning: Generate text to describe the main content of a given image/video.
- Localization tasks
- Temporal Language Localization: Given a video and a piece of text, locate the action described by the text (predict start and end time).
- Video Summarization from Text Query: Given a query (sentence) and a video, summarize the video based on the content of the sentence, predicting key frames (or key segments) of the video to compose a short summary video.
The multimodal model can extract and understand diverse types of information from videos such as images, sounds, text data, and behavioral cues. To illustrate its advantage, consider a video capturing a Husky dog eating dog food and barking:
Enhanced precision: Traditional single-modal visual models may confuse a husky with a wolf due to visual similarities. However, the multimodal model, by integrating barking sounds, visual cues, and identifying the text on the dog food package, can surely recognize the breed.
Deeper context recognition: The capability to process text information allows the multimodal model to identify the specific brand of dog food eaten by the Husky. This substantially enriches the indexed information, translating it to a richer search result.
Noise reduction: Multimodal models excel at handling ‘noisy’ or ambiguous data. For instance, if the dog’s mouth is obscured in the video, traditional action recognition models might struggle to decipher the action. But, a multimodal model can use the “chewing sound” data to accurately infer that the dog is eating.
Technical Challenges for Multimodal Models
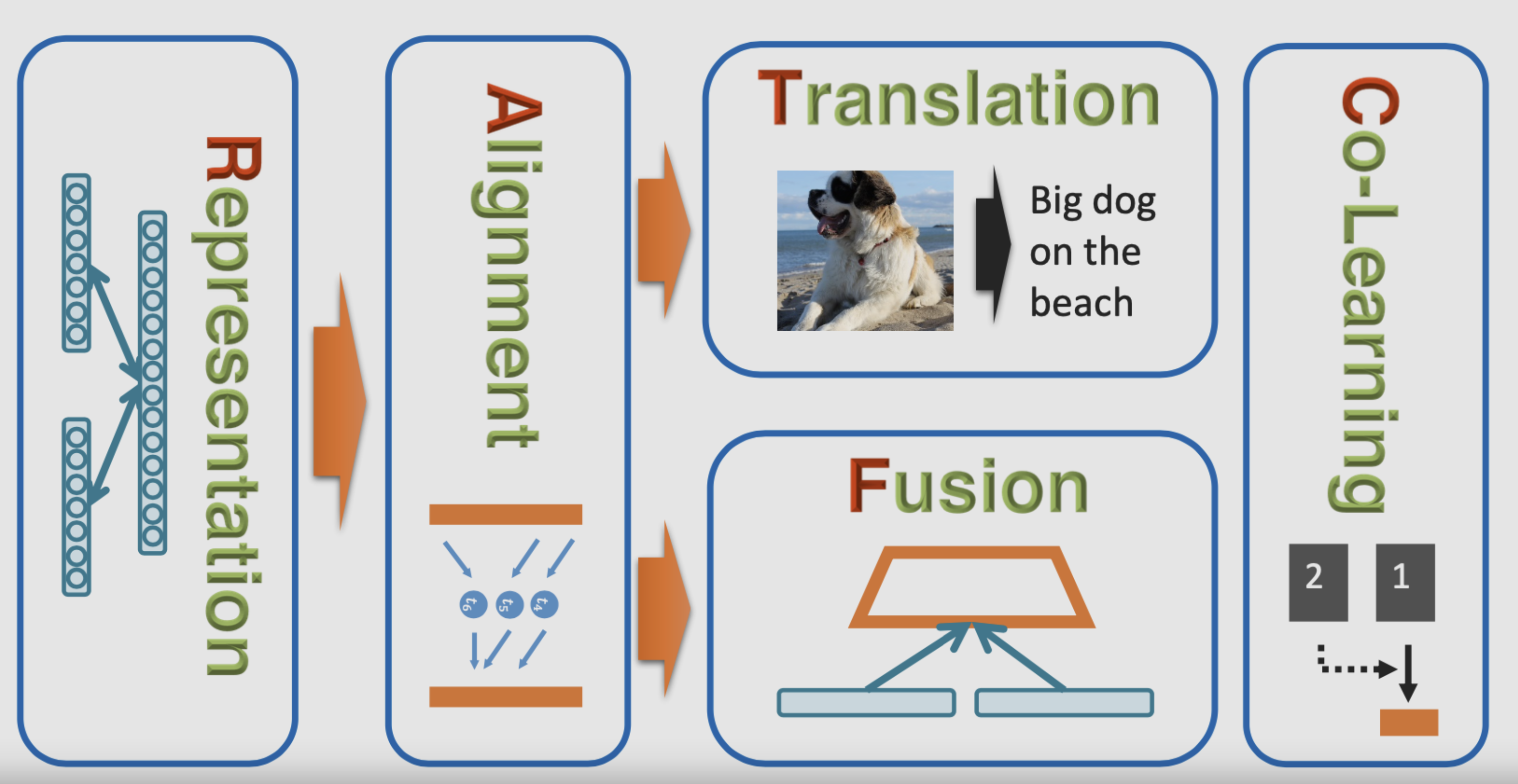
Representation
The first fundamental challenge resides in learning how to represent and summarize multimodal data, taking advantage of complementarity and redundancy among multiple modalities. The heterogeneity of multimodal data adds to the difficulty of constructing such representations. For instance, language is often symbolic, whereas audio and visual mediums are manifested as signals.
Single modality representations transform information into numerical vectors that computers can comprehend or further abstract into high-level feature vectors. Multimodal representations, in contrast, are about learning improved feature presentations by exploiting the complementarity among multiple modalities and eliminating the redundancy.
Translation
The second challenge involves mapping data from one modality to another. Data is not only heterogeneous, but the relationships among modalities are also often complex or ambiguous. There exists many correct manners to describe an image, and maybe there’s no flawless translation. Generally, instance-based or model-driven methods are utilized, the specifics of which won’t be delved into here.
Evaluation Dilemma in Translation
The prime challenge for multimodal translation methods is that they are tough to evaluate. Tasks like speech recognition have only one correct translation; speech synthesis and media description tasks do not. As is the case in language translation, multiple responses can be correct, and determining which translation is superior is often subjective.
- Manual evaluation is the ideal test, but it is costly and requires a diverse group of raters to avoid bias.
- Automatic metrics, including BLEU, Meteor, CIDEr, ROUGE, etc., are common alternatives in the image description realm, but their alignment with human assessment is proven weak.
- Retrieval-based evaluations and simplifying tasks (e.g., transform the one-to-many mapping in image caption to one-to-one mapping in VQA) also act as solutions to the evaluation problem.
Alignment
The third challenge resides in identifying direct relationships between sub-elements from two or more different modalities. For instance, one might wish to align the steps in a recipe with the corresponding segments of a video showing the dishes being prepared. To confront this challenge, we need to measure the similarity across different modalities and handle potential long-term dependencies and ambiguities.
Fusion
The fourth challenge is about making predictions by integrating information from two or more modalities. For instance, for audio-visual speech recognition, one might combine a visual description of the lip movements with the audio signal to predict the speech. Information from different modalities might have different predictive powers and noise topology, and data could be missing in at least one mode.
- Model-based Fusion Methods
- Deep Neural Networks: Enable end-to-end training incorporating LSTM, convolution layers, attention layers, gating mechanisms, and bilinear fusion to design intricate interactions of sequential data or image data.
- Multiple Kernel Learning: Utilize different kernels for different data modalities/views.
- Graphical Models: Implement Hidden Markov models or Bayesian networks to model the joint probability distribution (generative) or conditional probability (discriminative).
Co-learning
The fifth challenge is about transferring knowledge between the representations of modalities and their predictive models. Co-learning investigates how the knowledge learned from one modality can aid models trained over different modalities. This becomes critical when resources for one modality are scarce, like annotated data. The helper modality usually only participates in the model’s training phase, not in the testing phase.
SOTA Model - CLIP
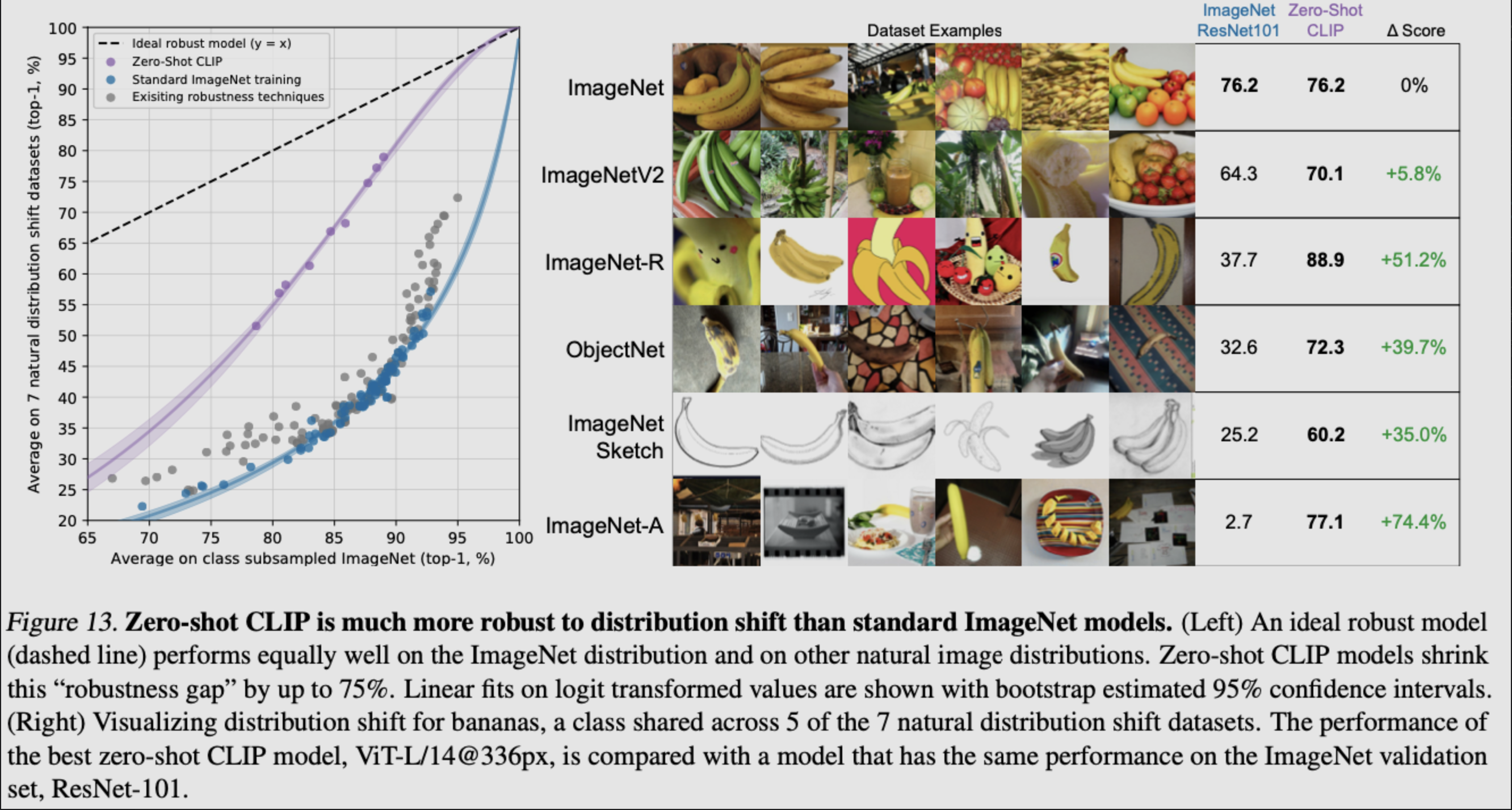
Let me introduce a cutting-edge SOTA model - CLIP (Contrastive Language-Image Pre-training). CLIP is OpenAI’s latest work combining NLP and CV, marking an important step forward in the multimodal field. Without using ImageNet’s data and labels for training, CLIP can still achieve the supervised training results of ResNet50 on the ImageNet dataset.
The primary contribution of CLIP is the adoption of unsupervised text information as supervision signals to learn visual features.
CLIP doesn’t predefine image and text label categories but directly uses the 400 million image-text pairs crawled from the Internet for training on image-text matching tasks. It has successfully applied the trained model to 30 existing computer vision categories.
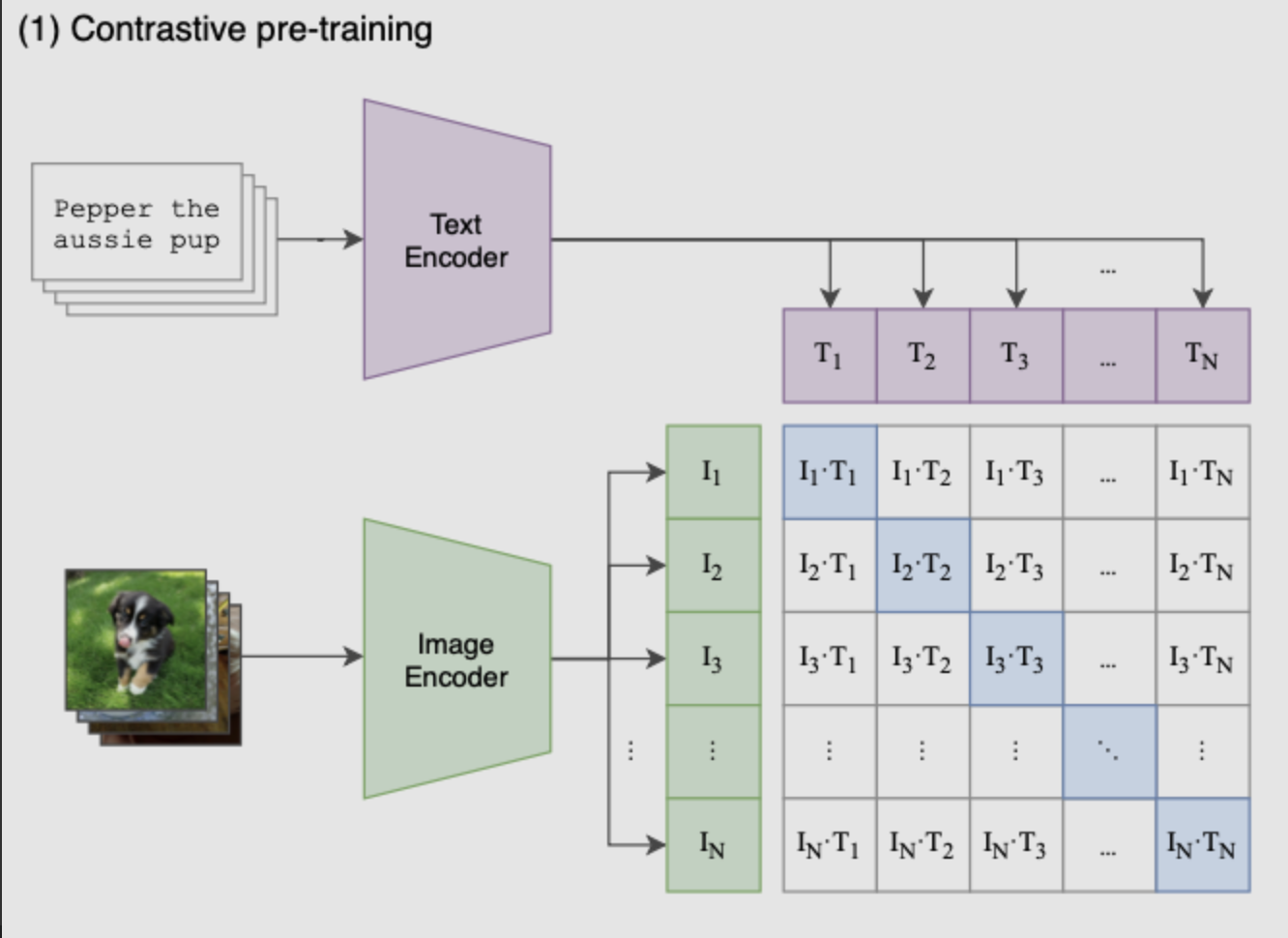
Phase 1: Contrastive Pre-training
During the pre-training phase, contrastive learning is flexible - only positive sample-pairs and negative sample-pairs need to be defined. Image-text pairs that can be paired will serve as positive samples.
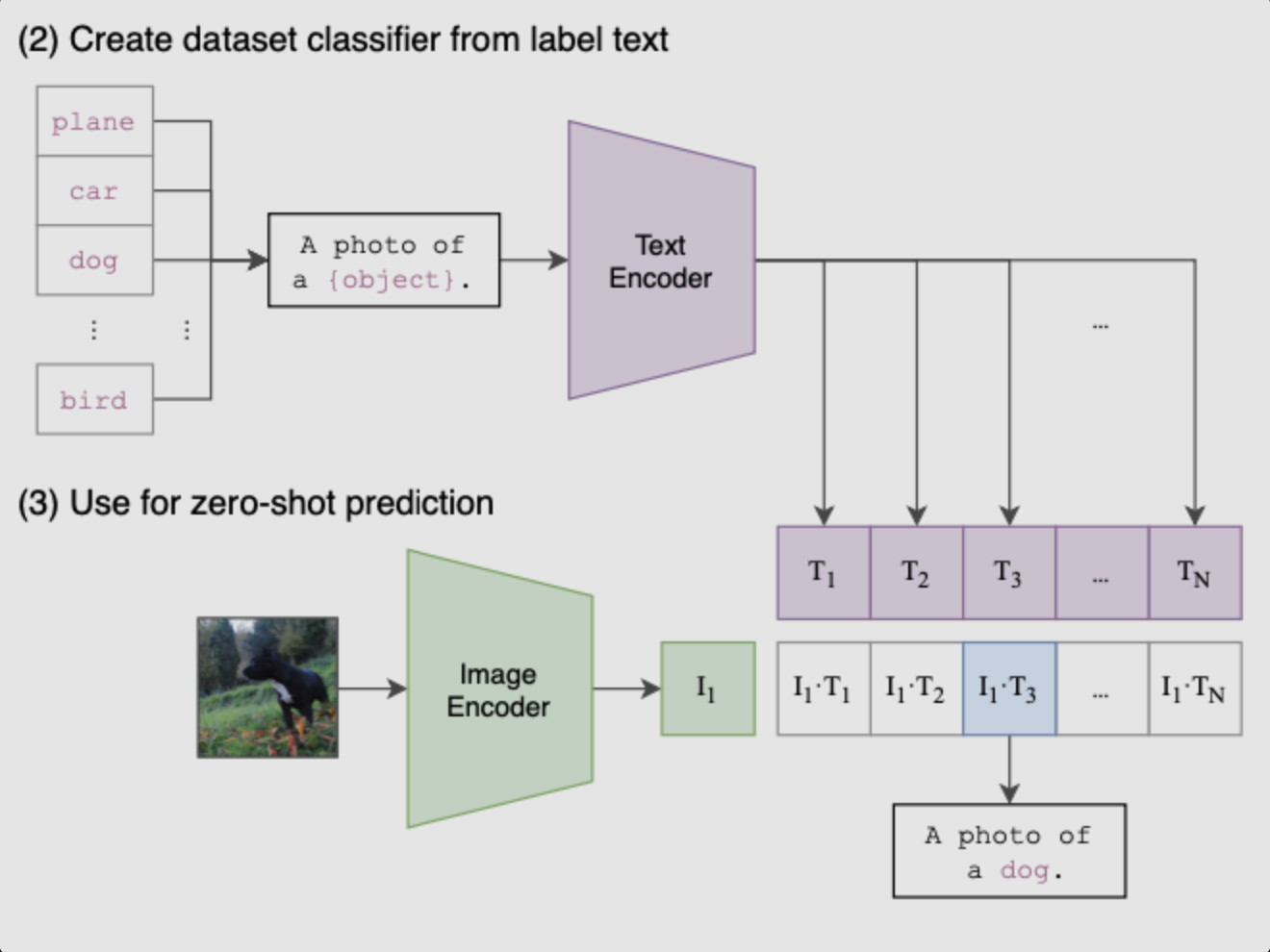
Phase 2: Create Dataset Classifier from Label Text
Based on the learnt prior on the 400M data, impressive image classification abilities can be obtained just from the label text of the dataset. Now that the training is complete, we transition to the forward prediction stage, using the prompt label text to create a text feature vector for classification.
Phase 3: Use for Zero-shot Prediction
Finally, it’s time to witness the effect of inference. For the test image, the category with the highest similarity is selected for output. During the inference stage, no matter what kind of image comes, as long as it is thrown into the Image Encoder for feature extraction, a one-dimensional image feature vector will be generated. Then this image feature is compared with N text features for cosine similarity, and the most similar one is the desired result, such as here, it should get “A photo of a guacamole.”
Reference
[1]multimodal-learning / zhanghao / blog



